How Big Data Supports Environmental Justice in Transportation

Two of the questions we’re often asked here at StreetLight Data are: “What percentage of the population does your sample capture?” and “Is the location data in your sample biased in some way, or does it fairly represent all groups?”
We recently revisited the data that supports StreetLight’s Metrics to examine how representative it is. Our analysis shows that the location-based services (LBS) data we use closely represents the population at large – more so than typical surveys. Broader representation of all groups is an important benefit of big data in transportation.
Fundamentally, we believe (and research backs this up) that more equitable data and sampling will lead to more equitable transportation policies and infrastructure planning. These policies and plans have generational impacts due to the lifecycles of these investments.
As a very simple example, if no one from a certain block group is included in a survey then the planners may never know that it takes twice as long for that community to get to work compared to the average, and not take actions to correct this inequitable distribution of transportation and accessibility. If lower-income block groups are more often the ones not included, then a systemic community wide bias in allocation of transportation planning can develop.
The U.S. DOT includes a core principle of equitable transportation planning as “full and fair participation by all potentially affected communities in the transportation decision-making process.” If data is not collected from a group of people, they simply cannot fully participate.
Key Questions for Data Suppliers
When we evaluate LBS data to purchase from suppliers, our goal is to answer two key questions:
- What is the data set’s sample share? In other words, what percentage of a given region’s population uses the devices that create the location records in the sample?
- In terms of income, are the device users in the data set representative of the people who live there? In other words, do the incomes of the device users in our sample match the distribution of income levels of people living in that region?
- Also important (though not discussed here), what percentage of each sample devices’ trips are captured in the data set?
In this blog post, we will demonstrate how we answered the first two of these questions for the state of Florida. Florida is an excellent case study because it is a populous state with a diverse range of incomes, industries, and land uses.
While there are regional variations in our sample, our findings in Florida are similar to our findings for the rest of the United States. (Note: This post does simplify the actual algorithmic processing and data science performed, so apologies to our Data Science team!)
Device Penetration Rate
To determine device sample share rates for LBS data, our first step is to estimate the number of devices in our sample that “live” in a particular area. Next, we compare that number to the region’s total population per the most recent U.S. Census.
First, we look at devices’ locations during nighttime hours, when people tend to be near their residences. Based on how many nighttime hours devices spend there, we assign a probability that devices are affiliated with a particular Census block. A device is disaggregated, so 30% of it might belong to one block, 30% to another, and 40% to a third. For clarity’s sake: We do not have any personally identifiable data (just points in space and time) about device owners.
Our next step is to add up all the devices in our sample that are probably affiliated with each Census block. If we assign 15 devices to a given Census block that 100 people live in, that means our device sample share for that Census block is 15%. Since published StreetLight Metrics include only information about groups of people – even in blog posts – we aggregated all of the Census blocks in this study into tracts. Keep in mind that about 30 people live in the average Census block, and about 6,000 people live in the average Census tract.
Results for Florida: 13% Device Sample Share
Our average device sample share across all of Florida is 13.1%. This number holds very steady across the tracts. Figure 1 (below) shows a histogram for all 4,000+ tracts in the state of Florida. As you can see, 90% of tracts have a penetration rate between 6.0% and 20.0%. This is a very consistent sample.
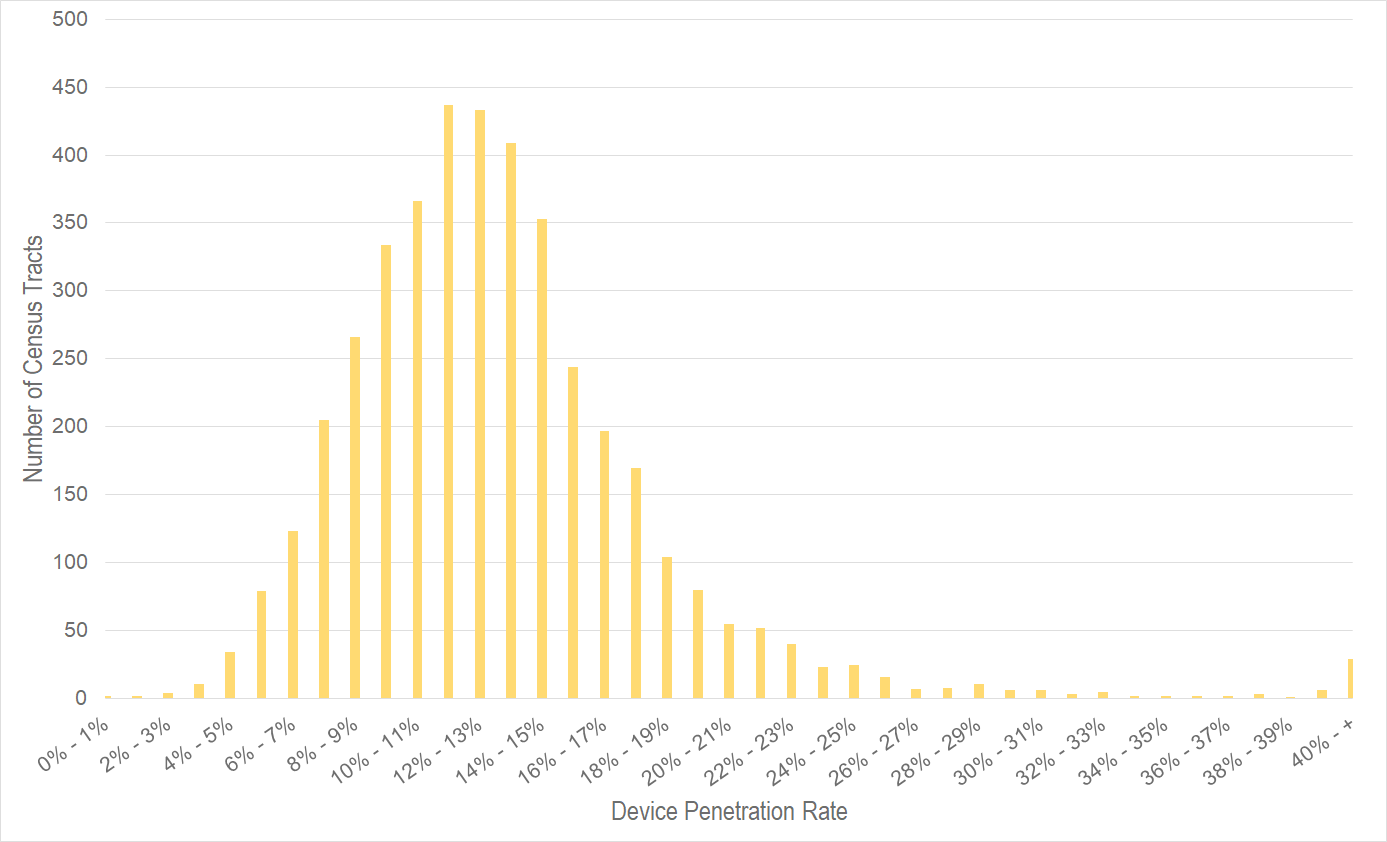
Figure 1: Histogram of Florida tracts by device penetration rate. StreetLight adjusts its sample to correct for the variance in tract penetration rate, so any StreetLight Metric accurately represents the general population.
This device sample share rate also impacts how we calculate our travel pattern analytics. If a device in a customer’s analysis is affiliated with a block with a 5% sample share, we’ll treat that device differently from a device that lives in a block with a 10% sample share. Essentially, our algorithms automatically scale our Metrics to account for our sample share rates at the devices’ Census blocks. If you would like details on this process, see our Data Sources and Methodology white paper.
In most of the U.S.. people tend to live near others like themselves. So by normalizing at a granular level for residential geography, we also normalize for demographics.
Digging Into Income Bias
When it comes to bias, our clients often ask first about income. Many of us in the transportation industry have spent years controlling for income bias in samples, and having a representative sample is a critical component of ensuring that transportation plans, infrastructure, and policies are equitable. So we take it very seriously! Keep in mind that this same type of bias analysis can be extended to other Census demographics.
To explore income bias in our sample, we use the same aggregate “device home-block locations” that we used for our sample share analysis. We focus on the block group level. In terms of population, block groups rank between Census blocks and tracts. The American Community Survey organizes its statistics for income by block group, and we use their statistics for this analysis.
Once we have our sample share by block group, we determine the average income of each block group. Our goal is to find out if our sample share is different across higher income and lower income block groups. For this case study, our answer is no – the penetration rate is similar across all income levels, as shown in Figure 2 below.
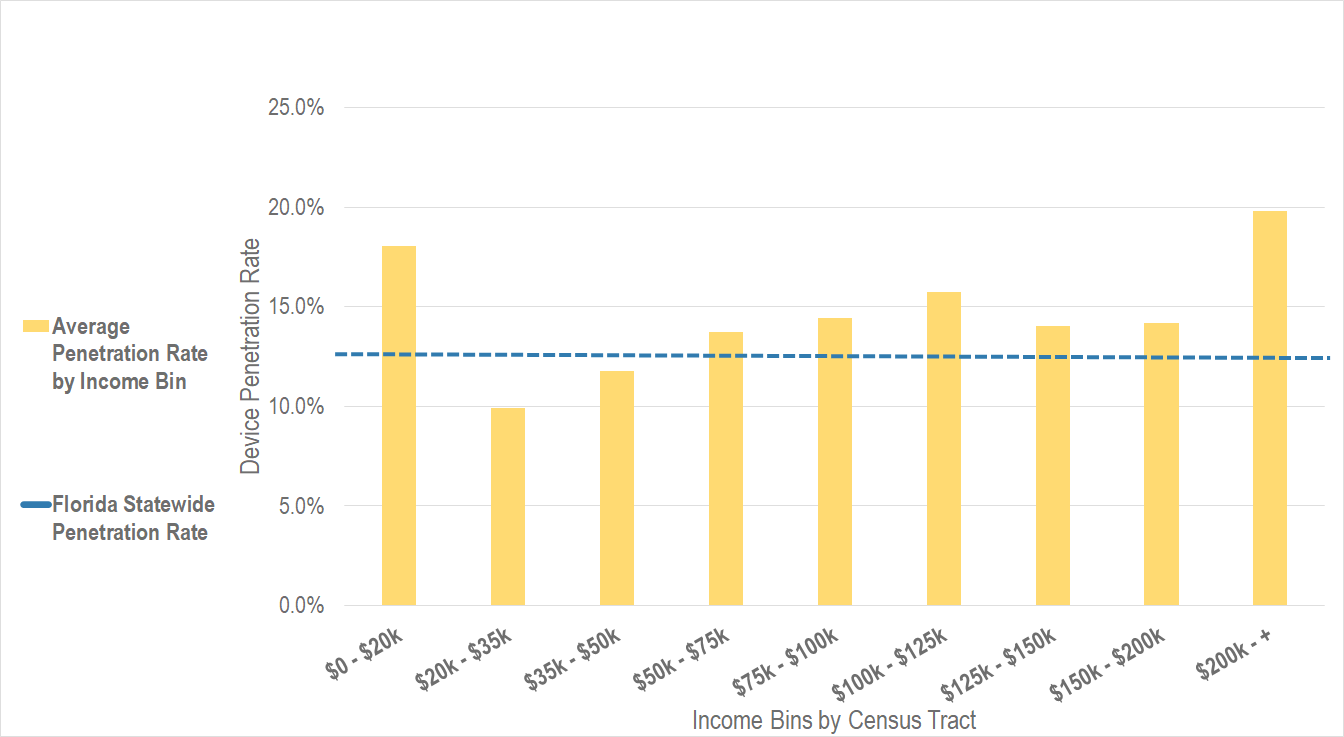
Figure 2: Device penetration rate by tract average income. StreetLight adjusts its sample to correct for this local difference in sampling by residential geography, so that any StreetLight Metric accurately represents the general population.
Importantly, our data is more evenly distributed and less biased than any household travel survey we have come across. This is for several reasons – bias in who chooses to answer a survey, language barriers, lower sample sizes in general, polling method (using landlines for example) and more.
These differences have been widely documented in the academic literature. For example, the 2017 Southeast Florida Household Travel Survey sample shows nearly 100x smaller sample penetration compared to ours, and the sampling rate for households making $75k and more was 3.2x the rate of households making $25k and less.
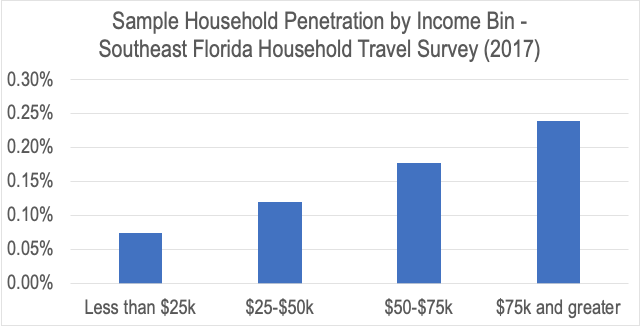
Figure 3: Southeast Florida Household Travel survey sampled higher income households at 3.2x the rate of lower income households, unlike StreetLight which has a very similar rate for high and low income. Also StreetLight’s sample covered ~100x more devices for many more days.
While the survey team followed all best practices in normalizing this biased sample it is simply much more difficult to normalize when sampling rates vary to such an extreme.
Digging Into Other Bias
Socio-economic factors include characteristics beyond income. We compared our StreetLight sample-device weighted percentages to the reported U.S. Census-population-weighted estimates for a handful of other demographic variables. The data is presented in the table below.
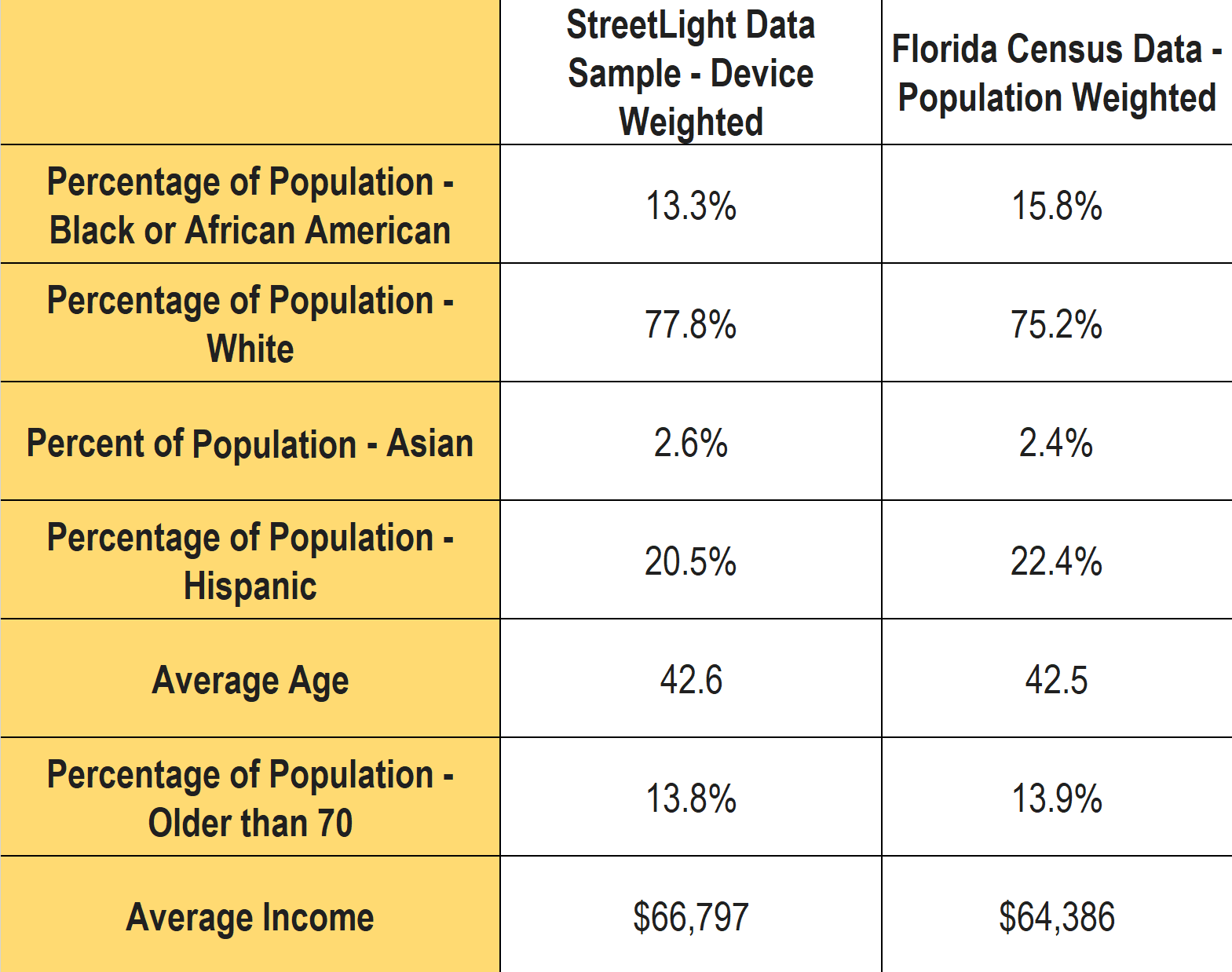
What we see in our data is that our sample for Florida closely represents the population at large. Another promising proof point that our data reflects the diverse characteristics of the geographies that our customers analyze with StreetLight. Lastly, it bears repeating that any metric that is expressed as StreetLight Volume has been normalized for any local bias or sampling variation.
Going Further: An Invitation to Explore Our Data
We’ve provided the “bird’s eye” view of our sample’s representativeness in Florida, and we also want researchers and analysts to understand how that plays out when the data is converted into StreetLight Metrics.
For more detail about the methodology and validation supporting our analyses, we invite you to explore our various white papers, and in particular Our Methodology and Data Sources.
1Note – the current StreetLight Indices for bikes, pedestrians, and trucks do not use the Census penetration for normalization, both use other grounding data instead. See the full documentation for details.